Curating a COVID-19 data repository and forecasting county-level death counts in the United States
Harvard Data Science Review (2020)
Abstract
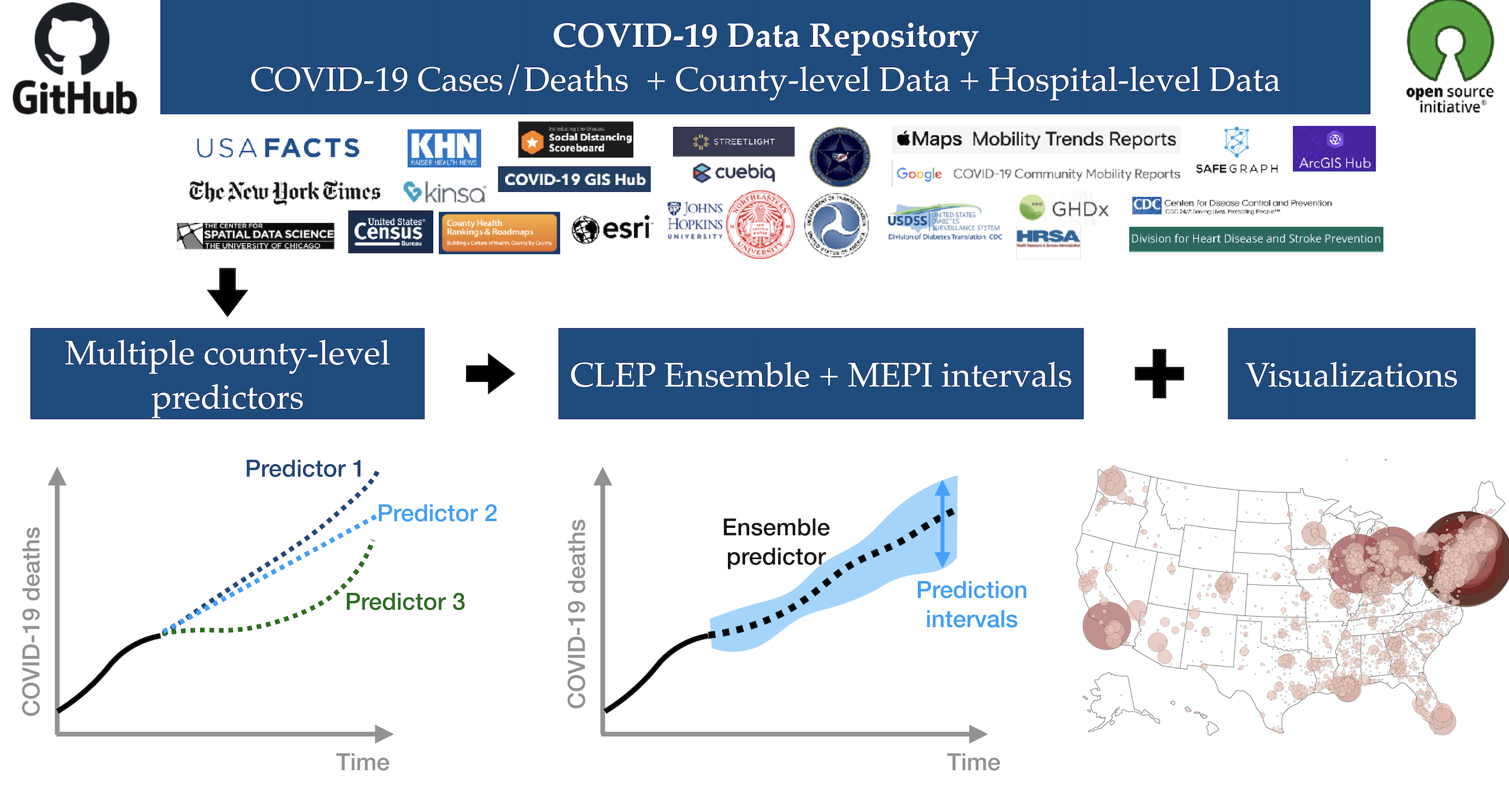
As the COVID-19 outbreak continues to evolve, accurate forecasting continues to play an extremely important role in informing policy decisions. In this paper, we collate a large data repository containing COVID-19 information from a range of different sources. We use this data to develop several predictors and prediction intervals for forecasting the short-term (e.g., over the next week) trajectory of COVID-19-related recorded deaths at the county-level in the United States. Specifically, using data from January 22, 2020, to May 10, 2020, we produce several different predictors and combine their forecasts using ensembling techniques, resulting in an ensemble we refer to as Combined Linear and Exponential Predictors (CLEP). Our individual predictors include county-specific exponential and linear predictors, an exponential predictor that pools data together across counties, and a demographics-based exponential predictor. In addition, we use the largest prediction errors in the past five days to assess the uncertainty of our death predictions, resulting in prediction intervals that we refer to as Maximum (absolute) Error Prediction Intervals (MEPI). We show that MEPI is an effective method in practice with a 94.5% coverage rate when averaged across counties. Our forecasts are already being used by the non-profit organization, Response4Life, to determine the medical supply need for individual hospitals and have directly contributed to the distribution of medical supplies across the country. We hope that our forecasts and data repository can help guide necessary county-specific decision-making and help counties prepare for their continued fight against COVID-19.